
This global warming stuff is getting to be really quite scary. 😫
Extreme Heat Event in Northern Siberia and the coastal Arctic Ocean This Week
•July 6, 2018 • Leave a CommentMonday’s eclipse & The Fight of The Century
•August 19, 2017 • Leave a CommentOn Monday March 8, 1971, Joe Frazier fought Muhammad Ali in “The Fight of The Century”. It was an event that was so popular that The Citizen’s Commission to Investigate the FBI used it to break into an FBI office and steal every file.
On Monday, a solar eclipse will cross the United States, with the zone of totality crossing from Washington to South Carolina. With millions of Americans stopping what they’re doing to look up at the sun for a few minutes – not quite as long as a boxing match – who knows what people will do?
Wheelbarrows of Money
•May 9, 2016 • Leave a CommentThe idea of just “printing money” to pay off the US Federal government debt is back in the news. Here’s a reminder of what that entails.
After reading my post about the “Depression Pocketbook,” my husband asked if I actually had any verifiable proof that anyone in Germany (or anywhere else) bought bread (or anything else) with a wheelbarrow full of money. It’s something we’ve both heard people say, but I must admit, I couldn’t quote a source.
Is it an urban legend? Is it something historians have invented because it sounds good? God knows when I was in school, I was told medieval people believed the world was flat. Not only was that never true (and there’s evidence from their maps and writings to prove it), but the idea can actually be traced back to a writer (I believe it was Nathaniel Hawthorne) who first used it in his popular biography of Christopher Columbus. It was taken for truth and repeated until it became reality and the truth became lost.
Is that what…
View original post 3,279 more words
Popping shell in a hospital
•March 22, 2016 • Leave a Comment…ok, it’s almost popping shell.
A few months ago, a family member was in the hospital for surgery. The hospital, New York Presbyterian, had courteously set up a computer for family members to use. However, it was running Windows XP, which is a no-longer-supported security nightmare.
Curious, I decided to investigate.
They’d disabled nearly everything. No “run” box, no explorer, nothing except an outdated copy of IE, and Office 2003. In the “Open” dialog, nearly every folder was empty. All modifications are dumped at logoff.
So, all the easiest ways to pop shell on this security nightmare are blocked off. They at least made some effort to secure things. It’s time to look into the wonderful rabbit hole that is Excel.
The wonderful thing about Excel is that it’s extremely flexible: Even an ancient version of Office (2003, which is what they had) can embed ActiveX controls, it can run Visual Basic, it can attach any of the Windows common controls as inputs to individual cells, and many other things.
The dangerous thing about Excel is (also) that it’s extremely flexible: Every single feature increases the attack surface, and exponentially complicates security.
In this case, the ability to embed a hyperlink is the most useful feature for me. Because of the way Windows Explorer/Windows Shell works, we can point a hyperlink at a local file, and the shell will execute the action associated with that file. If the file is an html file, Windows will open it in IE; if it’s a txt file, Windows will open it in Notepad; if it’s an exe file, Windows will execute it. I think you can see where I’m going with this.
When I attempted to “customize” the link, excel popped a version of the Common File Dialog… but all accessible folders were empty!
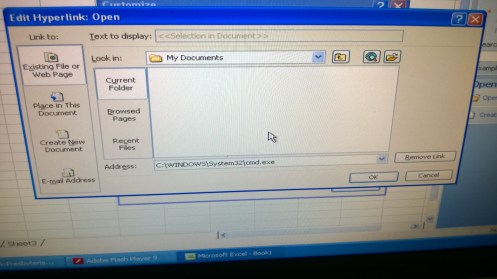
The “My Documents” folder, like every other browsable location, is devoid of clickable items.
So they’ve clearly tried to shrink the attack surface by hiding every clickable file, which has some value.
But again, Windows Shell link/path handling features are here to help me sneak past their security.
If you type the full path to a file in the “Address” field (or, more generally, the “Name” field), and then click OK (or, “Open”/”Save”), Windows accepts the (valid) path, and closes the dialog.
Opening the link then executes cmd.exe:
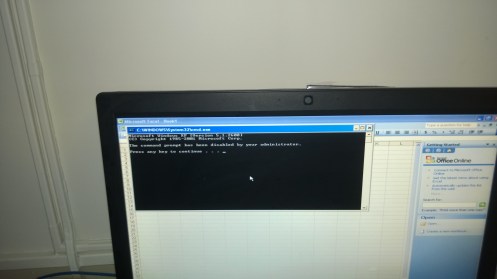
Tada! Command prompt opened… kinda
They (thankfully) have “disabled” the command prompt, which means I can’t easily use it to do any harm. There’s probably a way around it, but I was satisfied with getting CMD.exe to execute at all, and so I went on my way.
1984… 1993… 2016.
•February 19, 2016 • Leave a CommentYesterday on Bloomberg West, Nico Sell said: “I believe that Tim Cook is saving [more] lives” [than the FBI, in rejecting the court order]
![]()
I remember seeing the Apple commercial back in the day when it came out that depicted 1984 as the catchy advertising plot point for the Mac computer at the time. If only Woz and Jobs has known just how prophetic those images would be today. I remember too back in 1993 when the idea was floated and a governmental movement began to have a back door (aka a clipper chip) inserted into systems to allow access by the government *cough NSA cough* to be able to see the “evil doers” and stop them. I also remember the sane stopped that from happening. Well, that was then and this is now, well past 9/11 and nigh on 16 years later, we are faced with not only a government toying with the idea again but a federal body demanding through writ of law that a company break the system they have created…
View original post 703 more words
Why Does Hot Water Freeze Faster Than Cold?
•December 16, 2015 • Leave a CommentMany years ago I had to take a day off School to travel down to Cambridge in order to be interviewed for a place on the Natural Sciences Tripos at Magdalene College. One of the questions I was asked was the following:
If you put a bucket of hot water and a bucket of cold water outside on a freezing cold day, which would freeze first?
I think I gave the right answer, which is that it’s not obvious..
My main argument was that evaporation would increase the rate of cooling of the hot water and also mean that when it did get down to freezing point there would be less of it to freeze. I attempted to work something out based on the heat capacity of liquid water versus the latent heat of freezing, but didn’t get very far with that as I couldn’t remember any numbers. I do…
View original post 498 more words
Luck Has Nothing To Do With It
•November 14, 2015 • Leave a CommentSex worker rights are human rights, and there can never be too many voices speaking up for them, nor too many occasions on which to speak. – “Never Too Many”
 It’s that day again: Friday the 13th, the day on which I ask non-sex workers to speak up for us. As I’ve explained many times before, there is no possible way we can ever hope to win our rights without the help of allies; since only about 0.3% of the female population are whores at any given time (about 1% over their lifetimes), we simply don’t constitute a large enough voting bloc for politicians to give a damn about us, especially at a time when the popular fad is to pretend that we’re passive victims in need of “rescue” from our own choices. As I explained two years ago,
It’s that day again: Friday the 13th, the day on which I ask non-sex workers to speak up for us. As I’ve explained many times before, there is no possible way we can ever hope to win our rights without the help of allies; since only about 0.3% of the female population are whores at any given time (about 1% over their lifetimes), we simply don’t constitute a large enough voting bloc for politicians to give a damn about us, especially at a time when the popular fad is to pretend that we’re passive victims in need of “rescue” from our own choices. As I explained two years ago,
…the gay rights movement didn’t really…
View original post 496 more words
New Excuse
•October 17, 2015 • Leave a CommentThe most dangerous prohibitionists…are those who oppose no particular behavior or thing, but rather the very freedom of choice itself. – “Thou Shalt Not”
As I have pointed out many times in the past, all prohibitionism is the same:
…some object, substance or activity is depicted as intrinsically harmful regardless of context or actual outcome, a connection to children is invented if one does not exist, and the prohibitionists then argue that any abrogation of personal liberty (no matter how invasive) and any expansion of the police state (no matter how destructive, evil and counterproductive) is justified to stop the threat to Our Treasured Way of Life…
The primary tool used by prohibitionists to drum up support for their crusades is the Big Lie, a gigantic state-sponsored myth totally unsupported by facts which plays upon people’s primitive fears and tribalism to justify the criminalization of consensual…
View original post 799 more words
The stillness and solitude of a New York rooftop
•June 1, 2015 • Leave a CommentFew artists convey the disquieting solitude of city life like Edward Hopper, as he does here in “Untitled (Rooftops)” from 1926.

Hopper, who worked out of his studio on Washington Square until his death in 1967, was fascinated by urban scenes: “our native architecture with its hideous beauty, its fantastic roofs, pseudo-gothic, French Mansard, Colonial, mongrel or what not, with eye-searing color or delicate harmonies of faded paint, shouldering one another along interminable streets that taper off into swamps or dump heaps.”
