
React internals: Fibers
If you’ve ever worked with a complex framework like React, you might know that there’s a LOT going on behind the scenes to make everything work. Libraries like boost are infamous for their complexity, and the complex programming responsible for their useful features.
React, a javascript library for building entire frontend web apps, has the same complexity. It maintains an entire emulated DOM (to attempt reduction in browser-side re-rendering), extensions to Javascript (JSX, for embedded pseudo-html syntax), state management (to update the UI by comparing the emulated DOM with updates), and insanely complex backends for implementing everything uniformly.
Since Javascript is entirely (essentially, conceptually) single threaded, all of this has to be done without holding up the whole page. In many other languages (and on many other platforms) the way this is done is with threading and other parallel paradigms, which allow programers to explicitly run tasks in parallel. It’s very hard to get right, but every program we use on a daily basis makes use of it to ensure responsiveness and throughput.
Threading is typically implemented by lower level system constructs which actually schedule the work (running threads) by assigning them to specific resources (available processor time). Typically, this is handled by the operating system, which transparently pauses and resumes threads based on an incredible variety of system conditions and events. The exact nature of those conditions and events involve years worth of computer science, and are incredibly hard to implement correctly. Threads still need to communicate with each-other (for example, notifying a sleeping thread that work is available for it to do), and the program needs to use a system provided mechanism to do this.
Sometimes, and only rarely, programmers know enough about their application and about the systems they’re running on to take more control of the scheduling of tasks by manually pausing and resuming tasks. The concept here is called a Fiber instead of a Thread. Fibers yield (pause) themselves to other fibers when they cannot do anything useful, which can be vastly faster than waiting for the system to schedule another thread for execution. Usually, the system is actually much better than we are at scheduling, because it knows more about the machine it’s running on, and because many hundreds of thousands of hours of engineering effort have been put into optimizing thread scheduling.
However, in Javascript, the only (easy) mechanism of parallelism is through the event loop and the related (Promise-oriented) infrastructure, which isn’t really parallel anyways. Queueing a task is a non-blocking operation, but there’s no guarantee when it will run, or how long it will take to run. React solves this by manually breaking the tasks up and scheduling them – using React Fibers. Each fiber holds all the information needed to track, pause, and resume work. It contains that key element we’re supposed to assign to everything. It contains a member to store the local state of the element. The props for each element. Members for tracking rendering times – important for deciding when to pause and resume. It contains functions for creating fibers – and these are particularly important for organizing them later.
In some parts of the code, it’s really quite obvious (and neat) where this kind of manual scheduling is at work. In <a href="https://github.com/facebook/react/blob/6fbe630549de1ea7d2c34752880459f854c4440d/packages/react-reconciler/src/ReactFiberBeginWork.js#L689">updateClassComponent , the function first checks if there’s any work in progress (by checking a variable workInProgress), and later passes the nextUnitOfWork off to the next part of the program.
A common (and painful) part of this paradigm is that the program is constantly passing around state for context, here as the workInProgress variable. It’s constantly comparing work that is being done (workInProgress) to work that has been done (often times current), and tracking time spent in bits of work. Around here is also where props immediately come from. Essentially what React is doing is walking the tree of your components and scheduling a little bit of time for them to do the necessary work before React gives up on it and its children.
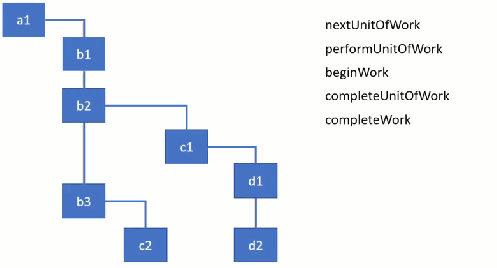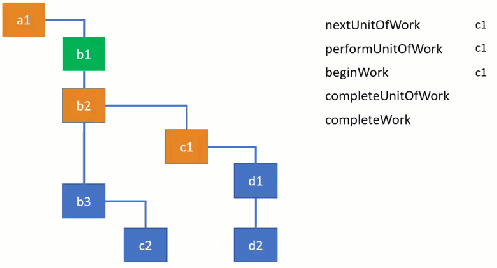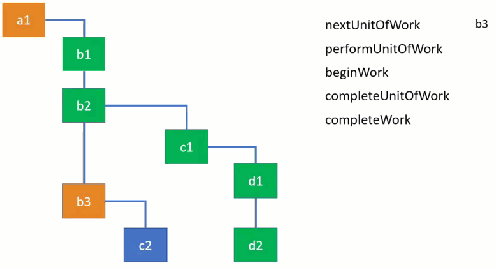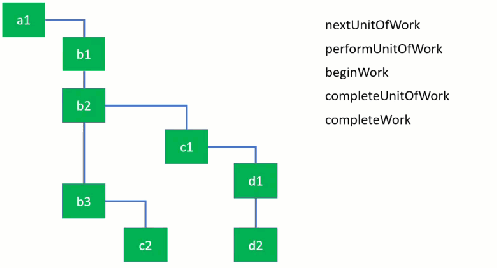
For us developers, this means that most of the the things we tell React to do don’t actually happen when React returns. It’s just saying “Yup, I’ll get around to it”, and sticks it in the tree.
Coroutines
I’m just gonna touch on this subject, because although they’re conceptually very complex, they can be a negative overhead abstraction for highly asynchronous code. Javascript now has some language support for implementing coroutines, which allow programmers to cleanly and simply suspend execution without managing callbacks, promises, continuations, and all that annoying complex stuff. This is possible because of Javascript’s support for yielding code, so we can return a value and then later jump back into the function at that same place:

It’s a little bit like having a goto:at the start of the function with a couple of if statements to decide where to jump to.
Sidenote: Javascript does (apparently) actually have something kinda similar to a gotostatement, the “label”, which can only be used with loops. Please don’t ever use it, but here it is for your entertainment:

…and weirdly:

…Please never use those, I will look for you, and I WILL FIND YOU if you do.
Anyways, there’s intense work going into async components for React, and lots of work going into making coroutines for React.
efwef
Good resources:
Inside Fiber: in-depth overview of the new reconciliation algorithm in React
Continuations, coroutines, fibers, effects
aeffaefae
