
querySelector vs getElementByID
A quirk of modern Javascript is that we have (at least) two ways of programmatically finding items in the DOM. querySelector is the newer of the two, dating to 2013, and is the more powerful one. It has a fancy syntax, and lets us write complex queries for groups of elements, classes, and subelements. But more powerful isn’t always more betterer.
It turns out that the added complexity means getElementByID is about twice as fast as querySelector. They’re both pretty fast, but I’m going to look into why getElementByID is faster.
In Chrome, getElementByID is actually a relatively simple operation:
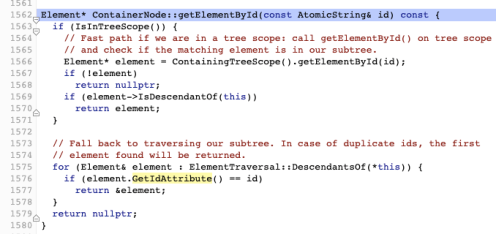
First, <a href="https://cs.chromium.org/chromium/src/third_party/blink/renderer/core/dom/node.h?l=622&rcl=2e5f1d247b8d38f84df51458ec78586455273dd8">IsInTreeScope is literally a single integer (enum) comparison just to check if the element target of getElementByID is already inserted in the DOM, in which case this is an easy task.

In this case, all Chrome really has to do is lookup the ID in an ordered map (elements_by_id) which is generally a really simple operation since the map is already constructed. In the event that the element hasn’t already been inserted, it falls back to traversing each descendant node in the target element (with some very slick C++ template/iterator magic).
querySelector
querySelector on the other hand, is a bit more work.

It immediately adds the query to a cache, because this is an expensive enough operation:

Original screencap from: chromium/src/third_party/blink/renderer/core/css/selector_query.cc
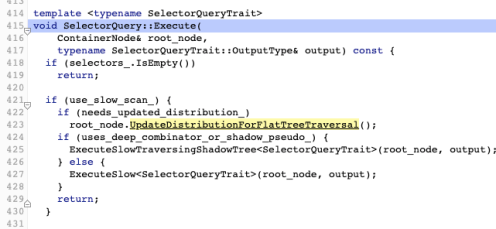
If it’s not in the cache, then things go off the rails get a bit more interesting, where it runs QueryFirst:

It looks simple, but there is actually an awful lot going on here. Honestly, I can’t tell what’s going on with NthIndexCache, since It’s not actually referenced anywhere, and it’s certainly not doing anything really nuts like _mm_prefetching data (which is a whole ‘nother can o’ worms).Execute however, is a fairly complex function.
It first has a slow path, where it checks every item in the tree with an inner function MatchSelector, a complex function that has to follow many rules:

There’s an awful lot going on here, it needs to do tons of work! Screencap from: chromium/src/third_party/blink/renderer/core/css/selector_checker.cc
Execute then has a (supposedly) faster path where it dispatches on the type of the selector (ID, class) to just “filter” the nodes that match. A bit better.

At the bottom there, FindTraverseRootsAndExecute is an awfully complex method that does a whole bunch more work, but uses some kind of history tracking to cache the work, with some complex bookkeeping logic.
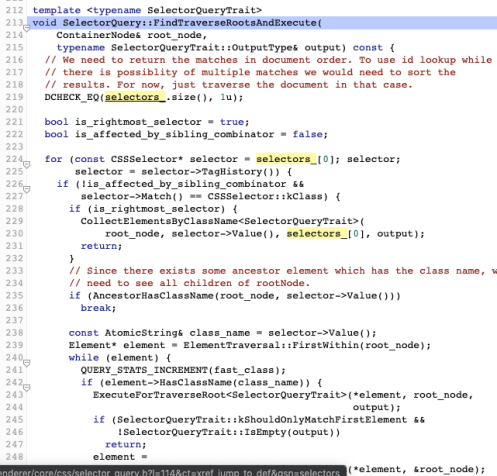
…wait, there’s even more to the function!

Really, this function is just doing fancy stuff to traverse the tree.
It doesn’t really matter
Thankfully, they’re both really fast. Like thousands of operations per millisecond fast. So none of this really matters other than as an exercise in browser internals 🙂
