
Ruby on Rails testing goes parallel – a deep dive!
If you ever work on large software projects, you’re bound to spend a LOT of time compiling code, running unit tests, and lots of other non-code stuff.

Since programming is really thought-intensive, any focus breaks are really disruptive. Even a ten second test suite is enough to break a train of thought. What can we do to improve that? Parallelize it of course!
One of my favorite achievements throughout my open source career has been speeding up my favorite programs. Parallelization has always yielded the best speedups for me, since few open source projects really take advantage of modern multicore systems. Lots of them were even written before home computers had more than one core!
The very first PR I submitted to speed up an open source project was more than 5 years ago now, in a project called termsaver. It’s a neat little python package that turns your terminal into a screensaver, and provides animations like a “matrix” code waterfall display, and a “hacker” source code typing animation. At the time I was running it with the Linux kernel source, and it would take several minutes to initialize the screensaver before actually beginning the animation. By parallelizing it, I brought it down to less than half a second.
In altWinDirStat, a hobby project fork of WinDirStat that I don’t have enough time to work on lately, I spent two years rewriting large parts of the application for improved performance, but the central feature was that it enumerated directories in the tree asynchronously. Instead of checking one directory at a time, altWinDirStat uses all system cores to submit new enumerations whenever it encountered a new directory in the tree, which moves the bottleneck from the CPU (where it shouldn’t be), to the I/O system (where an I/O operation should be). In the end, I reduced the runtime from hours to seconds.
Right now, while working on Ruby code, I’m getting the performance bug again. Complex test suites can run for several hours.
If you’re running rails, you’re in amazing luck, since Rails 6.0.0 beta now has parallel testing built right in!. You can see the PR here. They make this rails stuff amazingly easy. (Personally, I dislike that they use fork, but I digress.)
That said, I’m using RSpec right now. So it’s not quite built in, but it’s really easy nonetheless. There’s a gem to install, parallel_tests, that will easily parallelize them for you.
All you have to do to set it up is recreate your databases with rake parallel:create, copy the database schema to the new test database with rake parallel:prepare, and then you can run the tests in parallel with rake parallel:spec. It’s not super smart: there’s no fancy task stealing, shared queues, or anything fancy like that. It just evenly splits the tests into equally sized groups, and then assigns them to their own processors.
Internally, Ruby does parallelism a lot like Python. Ruby can’t really do a lot at once because it has a Global Interpreter Lock (exactly what it sounds like, it’s basically single threaded!), and it thus has to distribute tasks across several Ruby processes to implement parallelism.
Parallel_tests uses another gem (parallel) written by the same author to implement the core of the parallel logic. First, parallel queries the number of processors on the system using the builtin etc module (a C module, source here) …but as a side note, parallel does some weird things if you ever want to know the number of physical processors:
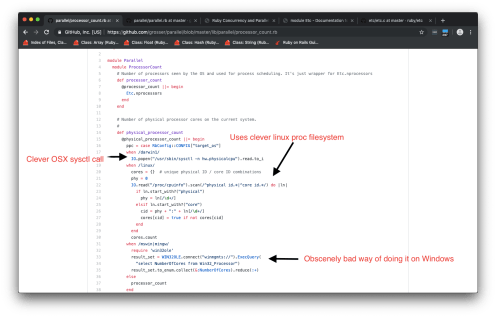
Windows has much more reasonable ways of doing this than through the Windows Management Instrumentation service. Source file: https://github.com/grosser/parallel/blob/master/lib/parallel/processor_count.rb
…and then, the runner method quickly calls into <a href="https://github.com/grosser/parallel_tests/blob/master/lib/parallel_tests/cli.rb#L54">run_tests_in_parallel</a> to actually get things started. This method first splits the tests to do work on into groups with <span class="pl-smi">@runner</span>.tests_in_groups, which immediately calls another subroutine <a href="https://github.com/grosser/parallel_tests/blob/9bf7d525bd4a6d9865e3664d95dd670c6ab76b73/lib/parallel_tests/test/runner.rb#L46">tests_with_size</a>. This method can either divvy them up blindly (according to the order they’ve been found), or it can do something kinda clever:
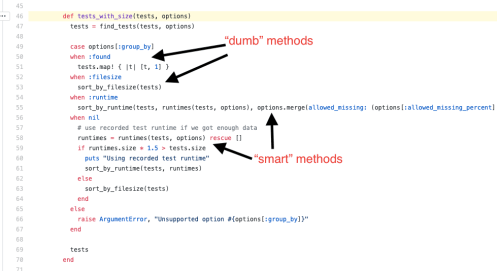
Clever sorting by runtime. Source file: https://github.com/grosser/parallel_tests/blob/9bf7d525bd4a6d9865e3664d95dd670c6ab76b73/lib/parallel_tests/test/runner.rb
If it has data about how long the tests take, it will more intelligently distribute them to separate processors. Thus, longer running tests don’t get grouped together to run serially on the same processor. Since this is process-level parallelism, this is the best way to balance the load. A better implementation would have some form of threadpool to dispatch the tasks to in real time, but that’s another post for another time.
Once everything has been set up correctly, we begin actually running the tests. The function responsible is execute_in_parallel, which dispatches back to the parallel gem’s map to actually run the tests. Internally, map decides whether to use multiple processes (the proper way to do it in ruby), to use threads (slower in ruby), or even to error out and run things serially.

Error path highlighted. Source file: https://github.com/grosser/parallel/blob/master/lib/parallel.rb#L262
It then uses a JobFactory to actually manage the work to be done by packaging the tasks as lambdas in a nice queue. The job factory object gets passed to <a href="https://github.com/grosser/parallel/blob/master/lib/parallel.rb#L372">work_in_processes</a>, which does the nitty-gritty of actually calling the workers. Once all the work is done, then parallel_tests does the boring work of actually collating the results, which I think is a boring process, so I won’t cover it.
Next time, I’ll show you an example on a large project with long running tests.
